![[딥러닝 스터디] 임베딩이란](/image/Elegant_Background-2.jpg)
[딥러닝 스터디] 임베딩이란
다음의 책을 공부하며 정리한 내용입니다
- 한국어 임베딩 - 이기창
1장. 임베딩이란
: 임베딩이란 자연어를 벡터로 바꾼 결과 혹은 그 일련의 과정 전체를 의미하는 용어이다.
임베딩에는..
- 말뭉치(corpus)의 의미, 문법 정보가 응축되어있다.
- 벡터이기 때문에 사칙연산이 가능하다
- 단어/문서 관련도를 계산할 수 있다.
대규모 말뭉치(corpus)를 미리 학습한 임베딩을 다른 문제를 푸는 데에 재사용 할 수 있다(전이학습)
임베딩 품질이 좋으면 단순한 모델로도 원하는 성능을 낼 수 있다. 따라서 자연어 처리 모델의 구성과 서비스에 있어 가장 중요한 구성요소 중 하나는 임베딩이라고 꼽을 수 있다.
임베딩 소스코드 내려받기 : 다양한 논문 저자들이 공개한 실제 임베딩 코드를 통해 자신만의 임베딩을 구축할 수 있다.
1-1. 임베딩이란
임베딩이란 사람이 쓰는
자연어를 기계가 이해할 수 있는 숫자의 나열인벡터로바꾼 결과/일련의 과정을 의미한다.
이는 단어나 문장 각각을 벡터로 변환해 벡터공간으로 끼워넣는다 는 의미에서 임베딩이란 이름이 붙게 되었다.
가장 간단한 임베딩은 단어의 빈도를 벡터로 사용하는 것이다. 근대 소설 작품 몇 편에 나오는 단어 기차 , 막걸리 , 선술집 의 예시를 통해 알아보자.
| 구분 | 메밀꽃 필 무렵 | 운수좋은 날 | 사랑손님과 어머니 | 삼포가는 길 |
|---|---|---|---|---|
| 기차 | 0 | 2 | 10 | 7 |
| 막걸리 | 0 | 1 | 0 | 0 |
| 선술집 | 0 | 1 | 1 | 0 |
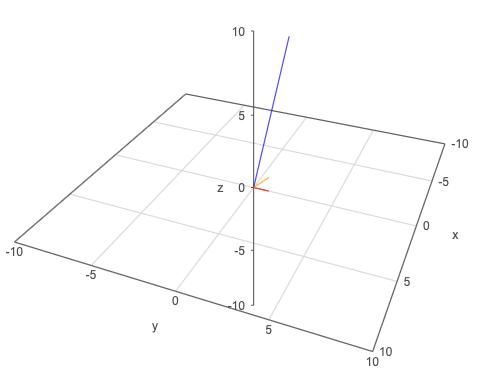
기차의 임베딩은 [0,2,10,7], 막걸리의 임베딩은 [0,1,0,0], 선술집의 임베딩은 [0,1,1,0]이다. 이를 바탕으로 우리는 기차(blue)-막걸리(red)간 의미차이가 선술집(orange)-막걸리(red)간 의미 차이보다 크다는 것을 알 수 있다.
1-2. 임베딩의 역할
임베딩의 역할은 위에서 언급한 것과 같이 크게 3가지로 분류할 수 있다.
단어/문장 간 관련도 계산
: 임베딩된 단어(벡터)는 단어 간 유사도를 계산할 수 있다.(코사인 유사도)
의미적/문법적 정보 함축
:
임베딩은 벡터인 만큼 사칙연산이 가능하다. 따라서 임베딩된 단어는 사칙 연산을 통해 단어간의 의미적/문법적 관계를 도출해낼 수 있다. 예를 들어 품질이 좋은 임베딩은 다음의 관계를 도출해낼 수 있다.아들 - 딸 + 소녀 = 소년
전이 학습
: 임베딩은 자주 다른
딥러닝 모델의 입력값으로 쓰인다. 이를 전이학습이라고 한다.
1-3. 임베딩 기법의 역사와 종류
임베딩 기법의 발전흐름과 종류는 다음과 같이 정리할 수 있다.
1) 통계기반에서 뉴럴 네트워크 기반으로
- 초기 임베딩 기법은 말뭉치의 통계량을 직접적으로 활용
- 최근에는 신경망 기반의 임베딩 기법이 사용된다 : 다음/이전/중간 단어의 예측을 해내는 과정에서 학습
2) 단어 수준에서 문장 수준으로
- 2017년 이전의 임베딩 기법은 대게 단어수준 모델이었다 : NPLM, Word2Vec, GloVe, FastText, Swivel 등
- 이는 동음이의어를 분간하기 어렵다는 문제가 있다 :
사람의 눈과하늘에서 내리는 눈은 엄연히 다르지만 임베딩 벡터는 하나. - 2018년 이후 문장수준 임베딩 기법들이 주목받았다 : BERT, GPT, ELMo
- 문장수준 임베딩 기법은 개별 단어가 아닌 단어 시퀀스 전체의 문맥적 의미를 함축한다. 따라서 단어임베딩보다 학습 효과가 좋다.
다의어 ‘bank’를 문맥에 따라 시각화한 모습. 의미가 다른 단어를 분리해 이해할 수 있다.
3) Pre-train/Fine-tuning 모델로
90년대 자연어 처리 모델 : 사람이 직접 모델의 입력값을 선정.
2000년대 이후 : 데이터를 통째로 모델에 넣고
입출력 사이의 관계를사람의 개입없이모델 스스로 이해해내도록 유도한다.이러한 기법을 엔드 투 엔드 모델 이라고 한다. 대표적으로 시퀀스 투 시퀀스 모델이 있다.
2018년 이후 : 엔드투 엔드 방식에서 벗어나 pretrain/fine tuning 방식으로 발전해나가고 있다.
대규모 말뭉치로 임베딩을 만든다(프리트레인)
: 이 말뭉치에는 단어의 의미/문법적 맥락이 포함되어있다.
임베딩을 입력으로 하는 새로운 딥러닝 모델을 만들고, 풀고자 하는 문제에 맞춰
임베딩을 포함한 모델 전체를 업데이트한다.(파인 튜닝, 전이 학습): ELMo, GPT, BERT 등이 해당
[용어 이해하기]
- 다운스트림 태스크 : 풀고자 하는 구체적 자연어처리 문제들. 품사판별, 개채명 인식, 의미역 분석 등이 있다.
- 업스트림 태스크 : 다운스트림 태스크에 앞서 해결해야할 과제. 단어/문장 임베딩을 프리트레인하는 과정이 이에 해당.
4) 임베딩의 종류와 성능
: 임베딩 기법은 크게 3가지로 나뉜다.
- 행렬분해 기반 방법
- 말뭉치 정보가 들어있는 기존의 행렬을 두 개 이상의 작은 행렬로 쪼개는 임베딩 기법
- GloVe, Sweivel등이 이에 해당
- 예측 기반 방법
- 어떤 단어 주변에 특정 단어가 나타날지 예측하거나, 이전/다음/중간의 단어가 무엇일지 맞추는 과정에서 학습하는 임베딩 기법
- 신경망 기반 임베딩 기법이 이러한 예측 기반 방법에 속한다 : Word2Vec, FastText, BERT, ELMo, GPT 등이 이에 해당
- 토픽 기반 방법
- 주어진 문서에 잠재된 주제를 추론하는 방식 의 임베딩 기법
- 잠재 디리클레 할당이 대표적 기법이다.