
Tensorflow 개발자 자격증 준비하기(3)
Image Classification
가위바위보 손 사진을 갖고 가위/바위/보자기로 이미지를 분류하는 classification 문제를 풀어보자. 이전과 마찬가지로 이미지 분류 문제입니다.
1. 문제
1 | def solution_model(): |
2. 기본 CNN모델 사용
: 케라스 책에 있는 고양이 vs 강아지 기본 분류모델을 사용했다.
[ 데이터 전처리 ]
: 단계는 다음과 같다. ImageGenerator 클래스를 사용한다.
- 사진 파일을 읽는다
- jpg컨텐츠를 rgb픽셀로 디코딩
- 부동소수점 타입의 텐서로 변환
- 0 - 255의 픽셀값을 [0, 1] 사이로 조정한다.
: 신경망은 작은 입력값을 선호한다.
1 | training_datagen = ImageDataGenerator( |
rescale=1. / 255: 모든 이미지를 1/255로 스케일 조정target_size=(150, 150): 모든 이미지 크기를 150 x 150으로 바꾼다class_mode='categorical': 다중분류일 경우 categorical, 혹은 sparse 사용. 이진분류는 binary사용.
1 | model.fit( |
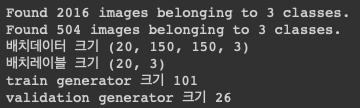
fit(): 첫번째 매개변수로 python generator를 받는다(ImageGenerator로 생성).steps_per_epoch: 하나의 에포크를 정의하기위해 사용할 배치의 수. 이 값만큼 경사하강법을 실시한다.- 여기서 20개의 샘플이 하나의 배치이므로 에포크 하나에서 샘플 2016개가 모두 처리되려면 101개의 배치가 필요하다.
- 이는 그냥 간단하게 len(train_generator)의 값이다.
validation_data: python data generator, 혹은 numpy tuple을 인자로 넘길 수 있다.
[ 사용한 모델 ]
1 | model = tf.keras.models.Sequential([ |
: 결과는 책에서 나온대로 70%대 초반정도의 정확도를 보여줬다. 이때 훈련 정확도와 검증 정확도, 훈련 손실과 검증 손실의 양상은 아래의 이미지와 비슷했다.


- 위의 두 그래프는 과대적합되는 모델의 양상을 보여준다.
- 훈련 정확도는 선형적으로 증가하여 100%까지 이르렀지만, 검증 정확도는 어느 지점에서 멈춰있다.
- 훈련 손실은 선형적으로 감소하여 0%까지 이르렀지만, 검증 손실은 선형적으로 증가/변화가 없다.
이러한 Overfitting문제를 컴퓨터 비전분야에서 해결하기 위해 일반적으로 사용하는 Data augumentation(데이터 증식) 방법을 사용해보도록 하자.
3. 데이터 증식 사용
데이터 증식: 기존 훈련샘플들을 변환함으로서 더 많은 훈련데이터를 생성하여 학습을 위한 샘플의 개수를 늘리는 방법
케라스에서는 ImageDataGenerator에서 이미지를 읽어들일때 여러 랜덤변환을 적용하도록 설정할 수 있다.
1 | ImageDataGenerator( |
- 회전각의 범위는
-rotation_range ~ +rotation_range이다 - height/width_shift_range는 전체 너비와 높이에 대한 비율값이다.
- 전단변환은 rotation_range로 회전할 때 y축 방향으로 각도를 증가시켜 이미지를 변형한다.
- horizontal_flip은 수평대칭을 가정할 수 있는 풍경이나 인물사진의 학습에 사용한다. 도로 표지판과 같이 뒤집힌 글씨를 학습시키는건 노노.
- fill_mode의 기본값인 nearest는 인접한 픽셀을 사용한다. 그밖에 constant, reflect, wrap등이 있다.
또한 모델에는 Dense layer직전에 Dropout을 추가한다.
4. 사전 훈련된 컨브넷 사용
완전 사기다 이건ㅋㅋ. 나쁜뜻이 아니라 성능이 너무 극적으로 좋아져서 사기라는 의미다. 실제 시험때 써도 될지 모르겠다.
방법은 그냥 간단하다. 사전 훈련된 합성곱 신경망을 가져와서 내 Dense layer classifier 앞에 넣어준다.
1 | from keras.applications.vgg16 import VGG16 |
모델은 아래처럼 간단해진다.
1 | model = models.Sequential() |
1 | Epoch 30/30 |
근데 학습시간이 어ㅓㅓ어어ㅓㅓ엄청나게 오래걸린다. 실제로는 못쓸듯…